By Harry Roberts
Harry Roberts is an independent consultant web performance engineer. He helps companies of all shapes and sizes find and fix site speed issues.
Written by Harry Roberts on CSS Wizardry.
N.B. All code can now be licensed under the permissive MIT license. Read more about licensing CSS Wizardry code samples…
Last week, I posted a short update on LinkedIn about CrUX’s new RTT data. Go and give it a quick read—the context will help.
Chrome have recently begun adding Round-Trip-Time (RTT) data to the Chrome User Experience Report (CrUX). This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions.
Round-trip-time (RTT) is basically a measure of latency—how long did it take to
get from one endpoint to another and back again? If you’ve ever pinged
www.google.com over in-flight wifi, you’ve measured RTT.
Latency is a key limiting factor on the web: given that most assets fetched by webpages are relatively small (compared to, say, downloading a software update or streaming a movie), we find that most experiences are latency-bound rather than bandwidth-bound.
The round trip also measures intermediate steps on that journey such as
propagation delay, transmission delay, processing delay, etc. These
intermediates fall outside of the scope of this article, but if you’ve ever run
a traceroute, you’re on the right lines.
RTT is designed to replace Effective Connection
Type
(ECT) with higher resolution timing information. To this end, it’s important to
realise that RTT data isn’t a measure of visitors’ latencies to your site, but
a measure of their latencies period. RTT is not a characteristic of your site,
but a characteristic of your visitor. It’s no different to saying this person
was from Nigeria
or this person was on mobile
or this person was
on a high latency connection
.
You can’t change that someone was from Nigeria, you can’t change that someone was on a mobile, and you can’t change their network conditions. RTT isn’t a you-thing, it’s a them-thing.
RTT data should be seen as an insight and not a metric. If you find that you have a large number of users on high latency connections, you need to build your applications sympathetically. That’s exactly what this article is about.
As the inclusion of RTT data is still in its infancy, viewing it isn’t yet as straightforward as other CrUX insights. However, there are a handful of ways available to us—some are, admittedly, more easy and free than others.
To see the 75th percentile RTT data for a given origin, you could use the CrUX API:
curl "https://chromeuxreport.googleapis.com/v1/records:queryRecord?key=<KEY>" \
--header 'Content-Type: application/json' \
--data '{"origin": "https://website.com", "formFactor": "DESKTOP", "metrics": ["round_trip_time"]}'
…replacing <KEY>, https://website.com, and DESKTOP with the relevant
inputs. For my site, I can see that my mobile RTT stands at 144ms and my desktop
RTT is 89ms—a difference that I can’t imagine we’ll find surprising.
If you don’t yet have a Treo account, you’re seriously missing out. Go and sign up. It’s a magical tool that makes life as a performance engineer so much easier (and much more fun). Treo has begun adding RTT data at the URL level, which is incredibly exciting:

Again, because RTT is a characteristic and not a metric, Treo does the smart thing and includes it in the Devices dashboard and not in, say, the Loading dashboard.
Dave Smart has built a great CrUX History visualiser over on his site Tame the Bots—you can go play around with it there and see both origin- and URL-level CrUX data, including the new RTT.
One particularly nice touch is his plotting RTT against TTFB—first-byte time includes one round trip, remember.

Before we dive in, I want to reiterate that this article is about general approaches to optimising high-latency experiences—it is not about improving metrics within the CrUX dataset. What follows is overall best-practice advice for designing with latency in mind.
This section details opportunist upgrades we can make that will hopefully improve latency-bound visitors’ experiences.
Broadly simplified…
Web servers don’t send whole files at once—they chunk them into packets and send those. These are then reassembled on the client. Each of these packets has its own RTT lifecycle (although not necessarily synchronously). This means that larger files that require more packets will incur more round trips—each round trip is latency. The speed at which files download will be a function of bandwidth and round trip time.
If you want resources to load faster on high-latency connections, making them smaller is still a sensible idea, although file size typically correlates more with available bandwidth as file sizes increase.
One of the most effective ways to reduce round trip times is to reduce the distance itself. I have a client in Prague who also hosts their site on-prem in the same city. They don’t currently have a CDN, yet they do experience high traffic levels from all over the globe:

Looking at their popularity rank, they’re more popular in certain sub-Saharan countries than they are in their own home country of Czechia! Getting this client set up on a CDN (probably Cloudflare) is one of my top priorities for this project.
As well as offering a whole host (ahem…) of other performance and security functionality, the primary benefit of using a CDN is simply geographic proximity. The less distance data has to travel, the faster it will get there.
If you aren’t using a CDN, you should be. If you are, you probably get some or all of the next sections for free anyway…
One of the first things a new visitor will have to do to access your site is resolve the IP address using the Domain Name System (DNS). As a website owner, you have a degree of control over who you use as your authoritative provider. Cloudflare manages my DNS, and they’re among the fastest. If possible, make sure you’re using someone who ranks highly.
Over 75% of responses served on the web are sent over HTTP/2, which is great! If you are one of that remaining 25%, you should prioritise it. By moving to a CDN, you’re likely to get HTTP/2 as standard, so that’s two birds with one stone.
A key benefit of HTTP/2 over HTTP/1.1 is better connection utilisation, which results in reduced overall connection negotiation.
HTTPs 1 and 2 both run over Transmission Control Protocol (TCP). When two HTTP endpoints want to communicate, they need to open a connection by way of a three-way handshake. This is almost all pure latency, and should be avoided where possible.
If we take my site’s current 144ms mobile round trip, opening a TCP connection would look like this:

The TCP would more accurately be a combination of SYN and ACK, but that’s beyond the scope of what I’m trying to illustrate in this article.
One whole round trip (144ms) before I can dispatch a GET request for a page.
An inefficiency present in HTTP/1.0 was that a connection could only satisfy one request–response lifecycle at a time, meaning fetching multiple files (as most webpages require) was a very slow affair.
To mitigate this, HTTP/1.1 permitted the opening of multiple simultaneous connections to a server at once. This number did vary, but is colloquially agreed to be six. This meant that a client (e.g. a browser) could download six files at a time by opening six connections. While this was overall faster, it introduced six times more cumulative latency by opening six separate TCP connections. One saving grace was that, once the connection was opened, it was kept open and reused (more on this in the next section).
You can visualise loading my homepage over an HTTP/1.1 connection below. Each of DNS, TCP, TLS can be considered pure latency, but I’m only talking about TCP right now.

Note that we open five connections to csswizardry.com, six to
res.cloudinary.com, and 23 TCP connections in total: that’s a lot of
cumulative latency! However, notice that the connections are reused (again, more
on that in the next section).
HTTP/2’s solution was to only open one TCP connection, greatly reducing the connection overhead, and allow many concurrent downloads by multiplexing streams within that connection:

Now we only have two connections to csswizardry.com (one needed to be CORS
enabled),
one to res.cloudinary.com, and 13 in total, all reused. Much nicer!
HTTP/2 reduces the amount of overall latency incurred by not having to navigate lots of new or additional three-way handshakes.
HTTP/1.0 is such a legacy protocol that I only really want to bring it up here as a piece of trivia. I truly hope no one reading is running over HTTP/1.0.
In HTTP/1.0, the problem was compounded by the fact that connections were immediately closed after use. This meant that every single file would need its own connection negotiating. Every single file incurred a whole bunch of use-once latency:

Connection: close to its responses.Each response has its own connection that gets immediately terminated. It really doesn’t get much slower than that.
Upgrade to HTTP/2, and ensure that any connections you do have to open are reused and persistent.
Hopefully you noticed something in the previous section: the connection was insecure. I briefly mentioned DNS earlier, and we looked a lot at TCP, so now it’s time to look at TLS.
In the terrifying case you are running HTTP and not HTTPS, get that fixed as a matter of urgency.
If we upgrade to HTTP/2, we have to also be running HTTPS—it’s part of the requirements. It’s safe to assume, therefore, that if you’re running HTTP/2, you’re also running securely. That does mean more latency, though…

This is now three round trips (432ms) before I can dispatch a GET request!
The additional layer of security is added onto the end of the TCP connection, meaning further round trips. I’d rather have
a secure site than a fast one, but if I could really choose, I’d choose both.
Simply by upgrading to TLS 1.3, we get access to built-in optimisations. TLS 1.3 cuts out an entire round trip by having removed some legacy aspects of the protocol:

Now it’s two round trips (288ms) before I can dispatch a GET request.
Faster. But not exactly fast. Let’s keep going.
An additional, optional feature of TLS 1.3 is
0-RTT for resuming previous connections. By sharing a Pre-Shared Key (PSK) in
the first handshake, we can send a GET request at the same time:

Now our GET request is dispatched after one round trip (144ms)!
Because of security trade offs, 0-RTT is an optional mechanism in TLS 1.3.
Security is vital, but it doesn’t have to be slow. Switch over to TLS 1.3 to get access to reduced round-trips on new connections, and potential zero round-trips on resumed connections!
By upgrading to HTTP/3, what we’re really getting access to is QUIC. HTTPs 1 and 2, as discussed, are built on top of TCP. HTTP/3 is built on top of QUIC, which implements a TCP-like layer on top of the inherently much faster UDP protocol. It’s all the safety and properness of TCP, but avoiding many of its latency issues. All of these changes and improvements are abstracted away from the day-to-day developer, and you do not need to alter your workflows at all, so I won’t elaborate on the differences between HTTP/2 and 3, or between TCP, UDP, and QUIC in this article.
I will say, though, that it breaks my heart that the pure elegance, time, and effort that has gone into protocol design is largely lost on end-user developers. We simply flick a switch somewhere and all of this stuff Just Happens™. We really don’t deserve it, but I digress…
That said, one of the key improvements in HTTP/3 is that, because it’s built on top of QUIC, which in turn has the benefit of access to the transport layer, it is able to provide TLS as part of the protocol. Instead of happening after our initial connection, it happens as part of it!

Our GET request is now dispatched after just one round trip (144ms)!
Here is a neat example of observing the parallelisation in DevTools: note that Initial connection and (the incorrectly labelled) SSL are parallelised and identical:

This means that HTTP/3’s worst-case model mimics TLS 1.3+0-RTT’s best case. If you have access to HTTP/3, I would recommend switching it on.
Not to be confused with, but because of, TLS 1.3+0-RTT, QUIC also has its own 0-RTT model. This is a result of QUIC folding TLS into the protocol itself. This cumulative effect of new protocol-level features means that resumed HTTP/3 sessions can make use of a 0-RTT model to send subsequent requests to the relevant origin:

Now, our request is dispatched after zero round trips (0ms). It doesn’t
GET (heh…) faster than that.
As if to make all of this even more impressive, QUIC gives us access to Connection Migration! The bad news?
No one currently implements it, but when they do…
Internet users, particularly on mobile, will experience changes in network conditions throughout their browsing lifecycle: connecting to a new cell tower as they walk through a city; joining their own wifi connection after arriving home; leaving a wifi connection when they leave a hotel.
Each of these changes would force TCP to negotiate brand new connections. TCP uses a four-tuple method to keep connections in sync, whereby the client’s IP address and port, plus the server’s IP address and port, are used to identify a connection. Any change in any of these four parameters would require a new TCP connection to be opened.
QUIC specifically designed its way around this by utilising a Connection ID to identify open connections, leaving it immune to changes in any of the four tuples. This, again, is thanks to QUIC being a ‘clean slate’ protocol.
This means that, rather than having to completely tear down and rebuild any current connections due to a network change, in our best-case scenario, HTTP/3 can seamlessly resume on an existing connection. That looks like this:
In an H/3 world, the worst case scenario is a one-round-trip connection. That’s a pretty great worst case:
If we were still running a TCP-based protocol such as HTTP/1 or 2, our best-case scenario would resemble a TCP 1.3+0-RTT setup:
Our worst case would likely be an HTTP/1 or 2 over TLS 1.2 scenario:
Tear everything down; do everything again.
HTTP/3’s underlying protocol, QUIC, is able to fold TLS into its design by default, eliminating the need to perform connection and TLS back-to-back. It can also provide genuine seamless connection migration as devices traverse the internet.
Alright! They were all fairly opportunistic upgrades, but what happens if a) you can’t upgrade your protocols or b) you’ve already upgraded everything you can? The best option, always, is to avoid. Prevention, as they say, is cheaper than the cure. How can we side-step latency entirely?
Avoiding too many HTTP requests was sound advice in an HTTP/1.1 world, where requests and connections were inherently limited. In the HTTP/2 world, we’ve been told we can take a slightly more carefree approach. However, where possible, avoiding unnecessary connections is still fairly wise.
Where possible, avoid going to third-party origins especially for anything on the Critical Path. I’ve said it before, and I’ll say it again and again until everyone listens: Self-Host Your Static Assets.
This client of mine has a huge gulf between TTFB and First Contentful Paint, and
a huge contributor to that is time lost to latency—negotiating new connections,
many of which are unnecessary and on the Critical Path (denoted by ![]() ):
):

Looking at the CrUX data, their visitors’ RTT times are in line with the slowest 25% of RTT times globally—this is a client who needs to optimise for latency. By self-hosting the majority of these resources, we can immediately regain a lot of ground.
Although connections aren’t as scary as they used to be, setting new connections up is pure latency—avoid doing so, particularly on the Critical Path.
Where at all possible, avoid redirects. Redirects are also pure latency. I’ve
seen scenarios before where developers author all of their hrefs to point at
a non-trailing slash, e.g.:
<a href=/products>View all products…</a>
…but their site’s URL policy contains a trailing slash, e.g.:
https://wwww.website.com/products/
This means that very link click a user makes will incur a full round trip of
latency in order to be served a 3xx-class redirect, which will then incur more
round trips to access the resource listed in the Location header:

I’d recommend looking into how many 3xx-class responses you serve—I’ve had
a number of clients this year alone who were, unbeknown to them, losing an
inordinate amount of time to redirects!
Interestingly, 304 responses are still a form of redirect: the server is
redirecting your visitor back to their HTTP cache. Ensure you aren’t wastefully
revalidating still-fresh
resources:

Cache-Control: public, max-age=0, must-revalidate. Hundreds
of milliseconds of pure latency. Ironically, as they’re all fingerprinted, this
client could have gone the complete opposite way: Cache-Control:
max-age=2147483648,
immutable. This was one of the first fixes I made on this project.The act of redirecting from http to https is very much mandatory and should
always be carried out regardless of any time penalty, but this can be sped up by
using HSTS, which we’ll cover shortly.
While sometimes unavoidable, redirects are also pure latency. Ensure you’re not causing unnecessary work, and tell your marketing department to stop using URL shorteners.
Non-simple HTTP requests are automatically prepended by pure-latency preflight
requests. Preflight requests are issued when the actual request meets certain
CORS conditions, such as emitting a non-standard request header, or attempting
to make a DELETE request, for example.
This is a common source of latency in single page apps that hit API endpoints.
Take this client for example: the requests to their API endpoint carry
a non-standard Accept-Version header. This automatically kicks off a preflight
so that the server is made aware of the incoming request and has an opportunity
to reject it.

The above preflight OPTIONS requests are made with the following request
headers (formatted for neatness):
Origin: https://website.com
Access-Control-Request-Method: GET
Access-Control-Request-Headers: Accept-Version
The server responds to the preflight request with a 204 containing the
corresponding response headers (formatted for neatness):
Access-Control-Allow-Origin: https://website.com
Access-Control-Allow-Methods: HEAD,
GET,
POST
Access-Control-Allow-Headers: Accept-Charset,
Accept-Encoding,
Accept-Language,
Accept-Version,
Authorization,
Cache-Control,
Content-Type,
Server-Id
This tells the browser that https://website.com is allowed to make requests of
the listed method types, and with the listed headers.
Once this has taken place—all pure latency—the browser can finally make the
actual request which carries an Accept-Version: 1.0 that the earlier preflight
had asked about.
Where possible, avoid making non-simple requests, as doing so will trigger a preflight that is pure latency. The conditions in which a request would trigger a preflight request are listed on MDN.
If you can’t avoid making preflight requests, read on.
If you’re building an SPA (which you probably are (and you probably shouldn’t be)), check what’s happening with your client-size API calls.
Even with the best will in the world, we will have to incur some latency. Techniques like 0-RTT only work for resumption, and hitting no other origins whatsoever is virtually impossible. So can we pay the latency cost up-front?
preconnectWe can use preconnect (sparingly) to preemptively open up connections to
important origins we’ll need to visit soon. I’ve written about configuring
preconnect before, so I’d
recommend giving that a read.
preconnect is a hint that the browser is going to need to open a new
connection to the supplied origin, and divorces the setup cost from the
initiating request:
<link rel=preconnect href=https://fonts.gstatic.com crossorigin>
That gives us this nice shift left in the waterfall:
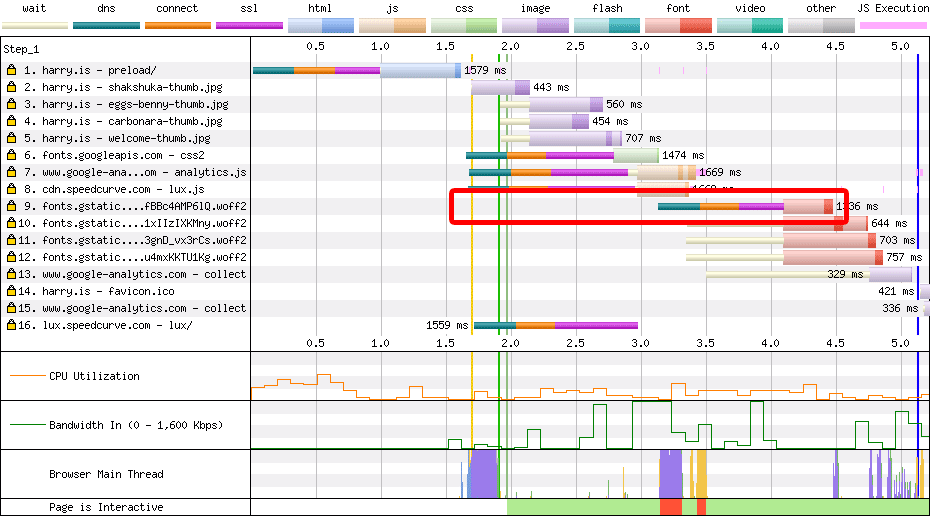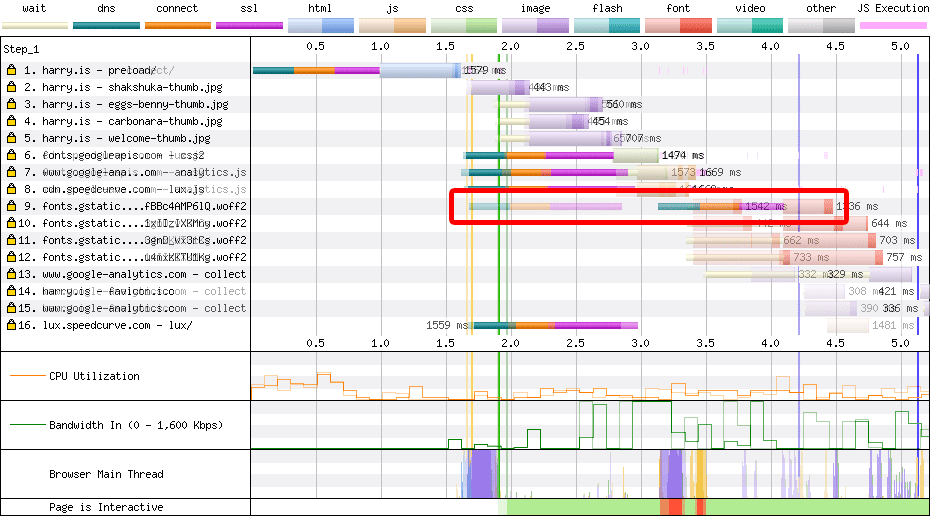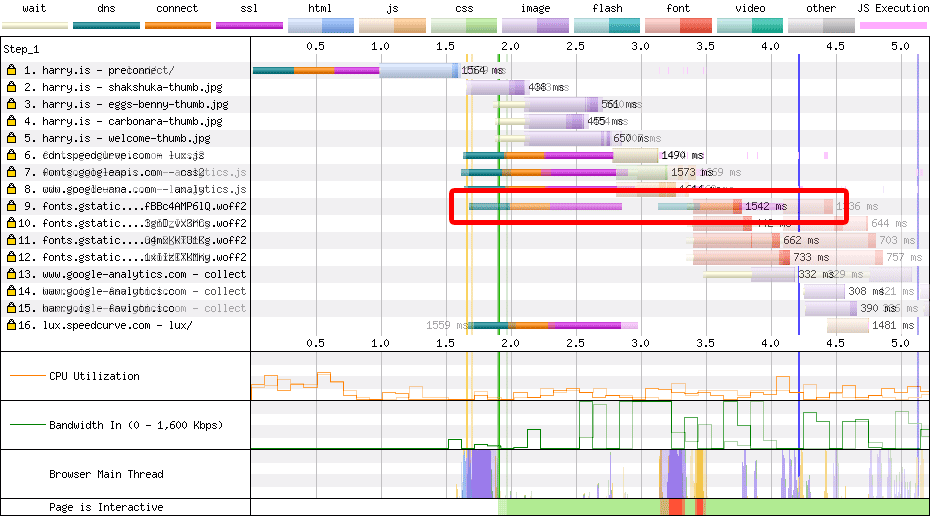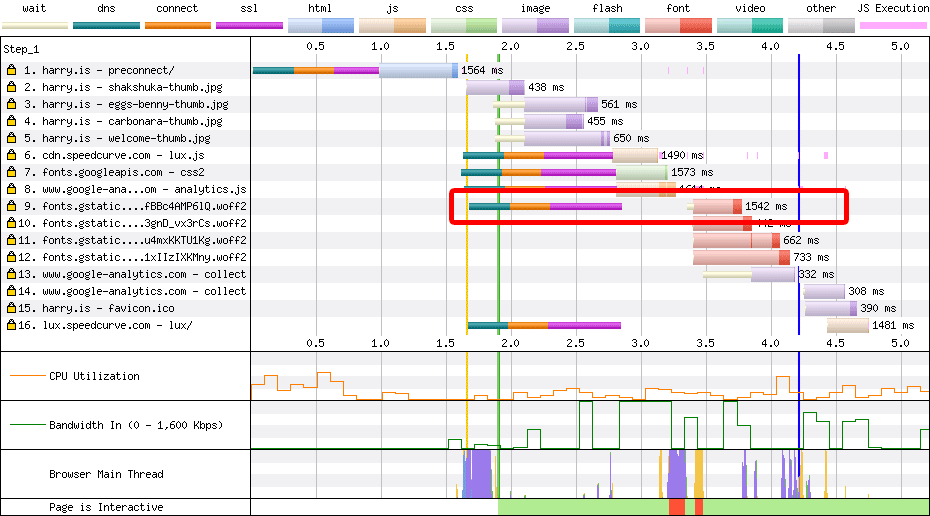
preconnect when speeding up Google
Fonts.Generally speaking, you’d only want to preconnect any origins that are
important to the page (Google Fonts, yes; Google Analytics, no) and things that
aren’t referenced early in the <head> already. Bonus points for deploying
preconnect as an HTTP
header
or Early Hint!
One step further than preconnecting the origin is to actually preemptively
fetch the resource itself using either of prefetch or prerender in the new
Speculation Rules API. This mechanism allows us to pay any latency penalties
ahead of time and behind the scenes, so by the time a user clicks through to
their next page, it’s hopefully already fetched and waiting.
I wrote about this
recently,
so again, I’ll point you to that, but remember to tread carefully. With things
like preconnect, prefetch, preload, and prerender, less is always more.
If you’re going to do something, try only do it once.
In the event we can’t make the relevant upgrades, and we simply can’t avoid incurring latency, then we’d better try really hard to cache the results of any latency-bound interactions…
The fastest request is the one that’s never made. Ensure you have a solid caching (and revalidation) strategy in place. I’ve written and spoken at length about HTTP cache so you can get everything you’ll need (and more…) from there.
CDNs only help solve latency if requests terminate there: anything that gets passed back to origin will remain on the slow path.
To fully maximise the benefits, ensure your CDN is configured to fully leverage
edge-level caching. If you need to set CDN (or shared) cache values separately
to your browser cache, use the s-maxage Cache-Control
directive.
The first time someone hits your site over http, they’re likely (hopefully)
going to get redirected to https. If you opt into using HTTP Strict Transport
Security
(HSTS), then you can get the browser to cache this redirection on their end,
meaning you don’t incur a latency-bound 3xx-class to nudge the visitor over to
your secure URLs in future.
HSTS is deployed by way of a Strict-Transport-Security response header, e.g.:
Strict-Transport-Security: max-age=31536000
Not only is this faster, it’s more secure.
To get even faster and even more secure, you can get your site added to the
HSTS Preload list. This hard-codes your origin(s)
into the browser so that there is never a first time http to https 3xx
redirect: you’ll never incur that latency (or exposure), not even once.
As before, if you can’t remove your preflight requests, you can at least cache
them. This works differently to your usual Cache-Control header, and is
implemented with the dedicated Access-Control-Max-Age response header. Give
its value serious consideration—this is an important security-facing feature. To
stop developers being too permissive, Firefox limits us to a maximum 24 hours
and Chrome to just two—even if you passed in 31,536,000 seconds (one year), the
best you’d get is 86,400 (one day):
Access-Control-Max-Age: 86400
These headers, much like any response header, are per-URL, so you can’t set an origin-wide policy (which is a feature, not a bug).
Any latency that can’t be avoided, take the hit once and deal with it. Subsequent occurrences should be mooted by virtue of being cached.
You have lots of options, but do remember that I just spent almost 5,000 words explaining how to solve what may be your least severe liability. Only if you know, and it’s very apparent, that latency is your biggest killer, should you embark on most of the items in this article.
My first recommendation would be to contain as many of your current problems as possible by aggressively caching anything expensive.
Next, work to avoid anything that you could subtly rework or refactor—it’s better to not do it at all, if we control it.
Things that can’t be avoided, attempt to solve out of band: preconnecting
origins, or prerendering subsequent navigations are real quick wins.
Beyond that, look to opportunist upgrades to get yourself ahead of the curve. Protocol-level improvements can swallow a lot of preexisting issues for us.
However, a lot of the things I have discussed are either:
If you’re interested in comparing the different protocol-level differences side-by-side:

Many thanks to Barry Pollard and Robin Marx for feedback and input on this article
Specs for the protocols discussed can be found at:
N.B. All code can now be licensed under the permissive MIT license. Read more about licensing CSS Wizardry code samples…
Harry Roberts is an independent consultant web performance engineer. He helps companies of all shapes and sizes find and fix site speed issues.

Hi there, I’m Harry Roberts. I am an award-winning Consultant Web Performance Engineer, designer, developer, writer, and speaker from the UK. I write, Tweet, speak, and share code about measuring and improving site-speed. You should hire me.
You can now find me on Mastodon.
I help teams achieve class-leading web performance, providing consultancy, guidance, and hands-on expertise.
I specialise in tackling complex, large-scale projects where speed, scalability, and reliability are critical to success.